EIF evidence standards
The EIF evidence ratings distinguish five levels of strength of evidence. This is not a rating of the scale of impact but of the degree to which a programme has been shown to have a positive, causal impact on specific child outcomes.
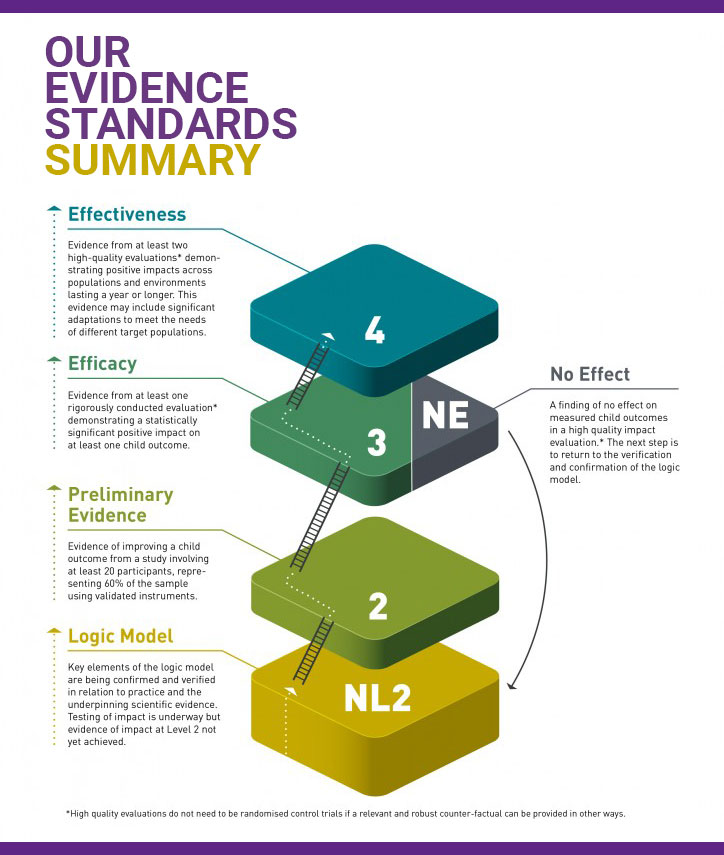
- Level 4 recognises programmes with evidence of a long-term positive impact through multiple rigorous evaluations. At least one of these studies must have evidence of improving a child outcome lasting a year or longer.
- Level 3 recognises programmes with evidence of a short-term positive impact from at least one rigorous evaluation – that is, where a judgment about causality can be made.
- Level 2 recognises programmes with preliminary evidence of improving a child outcome, but where an assumption of causal impact cannot be drawn.
The term ‘evidence-based’ is frequently applied to programmes with level 3 evidence or higher, because this is the point at which there is sufficient confidence that a causal relationship can be assumed. The term ‘preliminary’ is applied to programmes at level 2 to indicate that causal assumptions are not yet possible.
The rating of NL2 – ‘not level 2’ – distinguishes programmes whose most robust evaluation evidence does not meet the level 2 threshold for a child outcome.
The rating of NE — ‘found not to be effective in at least one rigorously conducted study’ — is reserved for programmes where a rigorous programme evaluation (equivalent to a level 3) has found no evidence of improving one of our child outcomes or providing significant benefits to other participants. This rating should not be interpreted to mean that the programme will never work, but it does suggest that the programme will need to adapt and improve its model, learning from the evaluation.
See also: How to read the Guidebook
A more dynamic description of these standards which recognises the importance of evidence development is shown in the following diagram (click to expand). This shows typical stages of development of evidence of effectiveness for a programme.
How did we create our evidence standards?
These standards were developed in consort with other What Works centres to assess interventions in terms of their impact and cost. They are broadly similar to the Maryland Scale and other critical appraisal systems that recognise stages of development, and were formally approved by our evidence panel during the set-up phase of the organisation.
It is also important to note that this approach differs from that taken by other evidence synthesis organisations (such as Cochrane, NICE) that make use of meta-analytic methods to synthesise findings from multiple interventions with similar aims and objectives. These alternative methods result in an aggregate score or statement thought to provide a robust estimate of the quality of evidence for a given practice type. They do not, however, facilitate comparisons between programmes on the basis of their evaluation evidence, as the EIF methodology does.
Full detail of evidence ratings
The following sections describe the criteria that are used to determine the evidence rating for a programme during assessment.
For assistance with interpreting a programme assessment, see: How to read the Guidebook
Level 4: Effectiveness
The programme has evidence from at least two rigorously conducted evaluations (RCT/QED) demonstrating positive impacts across populations and environments lasting a year or longer. The evidence may include significant adaptations to meet the needs of different target populations.
The evidence must meet the following requirements:
- The intervention has demonstrated consistent significant positive child outcomes in two rigorous evaluations (RCT/QED) meeting all criteria required for level 3.
- At least one evaluation uses a form of measurement that is independent of the study participants (and also independent of those who deliver the programme). In other words, self‐reports (through the use of validated instruments) might be used, but there is also assessment information independent of the study participants (eg, an independent observer, administrative data, etc).
- There is evidence of a long‐term outcome of 12 months or more from at least one of these studies.
To achieve a 4+ rating:
- All of the criteria for level 4 must be met.
- At least one of the effectiveness evaluations will have been conducted independently of the programme developer.
- The intervention must have evidence of improving EIF child outcomes from three or more rigorously conducted evaluations (RCT/QED) conducted within real world settings.
Level 3: Efficacy
The programme has evidence from at least one rigorously conducted RCT/QED demonstrating a statistically significant positive impact on at least one child outcome.
The evidence must meet the following requirements:
- The evaluation must meet the requirements for a Level 2.
- Participants are randomly assigned to the treatment and control groups through the use of methods appropriate for the circumstances and target population, OR sufficiently rigorous quasi‐experimental methods (eg regression discontinuity, propensity score matching) are used to generate an appropriately comparable sample through non‐random methods.
- Assignment to the treatment and comparison group is at the appropriate level (eg individual, family, school, community).
- An ‘intent‐to‐treat’ design is used, meaning that all participants recruited to the intervention participate in the pre/post measurement, regardless of whether or how much of the intervention they receive, even if they drop out of the intervention (this does not include dropping out of the study – which is then regarded as missing data).
- The treatment and comparison conditions are thoroughly described.
- The intervention is delivered with acceptable levels of fidelity in the evaluation study.
- The comparison condition provides an appropriate counterfactual to the treatment group.
- There is baseline equivalence between the treatment and comparison‐group participants on key demographic variables of interest to the study and baseline measures of outcomes (when feasible).
- Risks for contamination of the comparison group and other confounding factors are taken into account and controlled for in the analysis if possible.
- Participants are blind to their assignment to the treatment or comparison group. (Only a binding criteria if feasible.)
- The study should report on overall and differential attrition (or clearly present sample size information such that this can be readily calculated).
- If overall study attrition is greater than 10%, then study authors must report differences between the study drop‐outs and completers, as well as perform analyses demonstrating that study attrition did not undermine the equivalence of the study groups (and adjusting for this if differences are identified).
- Measurement is blind to group assignment.
- There is consistent and equivalent measurement of the treatment and control groups at all points when measurement takes place.
- Statistical models control for baseline differences between the treatment and comparison groups in outcome measures and demographic characteristics that might be apparent after recruitment.
- The treatment condition is modelled at the level of assignment (or deviations from that strategy are justified statistically).
- Appropriate methods are used and reported for the treatment of missing data.
- The findings are of sufficient magnitude to justify further analysis. (Not yet assessed in pure cost‐effectiveness terms.)
To achieve a 3+ rating:
- The programme will have obtained evidence of a significant positive child outcome through an efficacy study, but may also have additional consistent positive evidence from other evaluations (occurring under ideal circumstances or real world settings) that do not meet this criteria, thus keeping it from receiving an assessment of 4 or higher.
Level 2: Preliminary evidence
The programme has evidence of improving a child outcome from a study involving at least 20 participants, representing 60% of the sample, using validated instruments.
The evidence must meet the following requirements:
- Participants complete the same set of measures once shortly before participating in the programme and once again immediately afterwards.
- The sample is representative of the intervention’s target population in terms of age, demographics and level of need. The sample characteristics are clearly stated.
- The sample is sufficiently large to test for the desired impact. A minimum of 20 participants complete the measures at both time points within each study group (eg a minimum of 20 participants in pre/post study not involving a comparison group or a minimum of 20 participants in the treatment group AND comparison group).
- The study has clear processes for determining and reporting drop‐out and dose.
- For pre/post studies, overall study attrition is not higher than 40% (with at least 60% of the sample retained). For comparison group studies, overall study attrition is not higher than 65% (with at least 35% of the sample retained).
- The measures are appropriate for the intervention’s anticipated outcomes and population.
- The measures are valid and reliable. This means that the measures are standardised and validated independently of the study and the methods for standardisation are published. Administrative data and observational measures might also be used to measure programme impact, but there is sufficient information to determine their validity for doing this.
- Measurement is independent of any measures used as part of the treatment. The methods used to analyse results are appropriate given the data being analysed (categorical, ordinal, ratio/parametric or non‐parametric, etc) and the purpose of the analysis.
- There are no harmful effects.
- There is evidence of a statistically significant positive impact (p < .05) on at least one EIF outcome.
- The intervention’s model clearly identifies and justifies its primary and secondary outcomes and there is a statistically significant main effect of improving at least one or more of these outcomes, depending on the number of outcomes measured.
- There is consistency amongst the findings, resulting in few mixed results within the study.
- Subgroup analysis is used to verify for whom the intervention is effective and the conditions under which the effectiveness is found. (Statistically significant findings within subgroups are not treated as a replacement for a main effect.)
To achieve a 2+ rating:
- The programme will have observed a significant positive child outcome in an evaluation meeting all of the criteria for a level 2 evaluation, but also involving a treatment and comparison group.
- There is baseline equivalence between the treatment and comparison‐group participants on key demographic variables of interest to the study and baseline measures of outcomes (when feasible).
Not level 2 (NL2)
The programmes is judged to not meet the level 2 threshold for a variety of methodological reasons, including the representativeness of the sample and the validity and objectivity of the methods used to measure child impact in one of our seven child outcomes.
Programmes falling into this category are typically at earlier stages of their development, doing important foundational work.
No effect (NE)
The programme has evidence from at least one rigorously conducted RCT/QED that is also the most rigorous impact evaluation demonstrating no effect on child outcomes. The evidence must meet the following requirements:
- The evaluation must meet the requirements for level 3.
- It will have failed to confirm any statistically significant benefits with respect to at least one EIF child outcome.
In these instances, a rating of ‘no effect’ (NE) is applied to suggest that a rigorously conducted evaluation has failed to confirm positive benefits for parents or children.
Using the EIF evidence standards
We arrive at our strength of evidence ratings, measured against our evidence standards, through a detailed consideration of all significant evidence against 33 criteria, covering design, sample, measurement, analysis and impact. These evidence assessment criteria are intended to be applied by individuals who have been extensively trained in EIF programme assessment procedures. This process and our ratings are then subjected to rigorous quality assurance with independent experts. In our view, it is not possible to replicate this process externally.
The Early Intervention Foundation does not recognise, endorse or accept any liability arising from attempts to replicate our assessment processes or apply our standards by external organisations.
Background
The EIF assessment process was developed specifically to inform judgments about the extent to which a programme has been found effective in at least one rigorously conducted evaluation study.
These standards were developed in consort with other What Works Centres to assess interventions in terms of their impact and cost. They are broadly similar to the Maryland scale and other critical appraisal systems that recognise stages of development, and were formally approved by our evidence panel.
It is also important to note that this approach differs from that taken by other evidence synthesis organisations (such as Cochrane or NICE) that make use of meta-analytic methods to synthesise findings from multiple interventions with similar aims and objectives. These alternative methods result in an aggregate score or statement which is thought to provide a robust estimate of the quality of evidence for a given practice type. They do not, however, allow comparisons between programmes on the basis of their evaluation evidence, as the EIF methodology does.
Published July 2024